ГЛАВА 9 Выявление аномалий
Необходимость обнаружения необычных наблюдений (выбросов, или аномалий) во временных рядах часто возникает в таких ситуациях, как мониторинг состояния оборудования, отслеживание неожиданных колебаний на рынке ценных бумаг, учет показателей состояния здоровья пациентов и т.д. В этой главе мы рассмотрим один из инструментов для решения подобных задач — пакет anomalize. Для описания основ работы с этим пакетом воспользуемся данными по стоимости гостиничных номеров из таблицы hotels (подразд. 1.5.4).
9.1 Автоматическое обнаружение аномалий
Для начала попробуем обнаружить необычные наблюдения во временном ряду одной из гостиниц (например, с идентификатором prop_id = 13252). Для этого к таблице с данными (класса tibble, tibbletime или tsibble) необходимо последовательно применить команды с участием следующих функций из пакета anomalize:
time_decompose()— выполняет декомпозицию временного ряда на отдельные составляющие (сезонную, тренд и остатки; см. гл. 4);anomalize()— применяет к остаткам один из двух реализованных в пакете методов выявления аномалий (см. ниже);time_recompose()— восстанавливает исходный временной ряд, параллельно вычисляя верхнюю и нижнюю границы диапазона, в который входят “нормальные” наблюдения.
Получаемый в итоге объект имеет следующую структуру:
require(anomalize)
result_13252 <- hotels %>%
filter(prop_id == 13252) %>%
time_decompose(price_usd, merge = TRUE) %>%
anomalize(remainder) %>%
time_recompose()Разберемся подробнее, что именно произошло в результате выполнения приведенных выше команд:
- Результатом применения
time_decompose()к исходным данным стал расчет четырех столбцов:observed(исходные наблюдения моделируемой переменной),season(сезонная составляющая временного ряда),trend(тренд) иremainder(остатки). Параметрmerge = TRUEпривел к тому, что эти новые столбцы были добавлены к исходным данным. - Функция
anomalize()была применена к столбцуremainderи рассчитала три новых столбца —remainder_l1иremainder_l2(нижняя и верхняя границы, за пределами которых наблюдения считаются аномалиями), а также индикаторную переменнуюanomaly, которая принимает значение"No", если наблюдение не является выбросом, и"Yes"если является. - Функция
time_recompose()восстановила исходный временной ряд с использованием значений изseason,trend,remainder_l1иremainder_l2и попутно рассчитала два новых столбца:recomposed_l1иrecomposed_l2, которые соответствуют верхней и нижней границам диапазона “нормальных” наблюдений.
Суть всех этих вычислений станет понятнее, если мы представим результаты графически. Функция plot_anomaly_decomposition() изображает компоненты временного ряда, рассчитываемые функцией time_decompose(). На получаемом графике аномалии показаны в виде обведенных кружком красных точек (рис. 9.1):
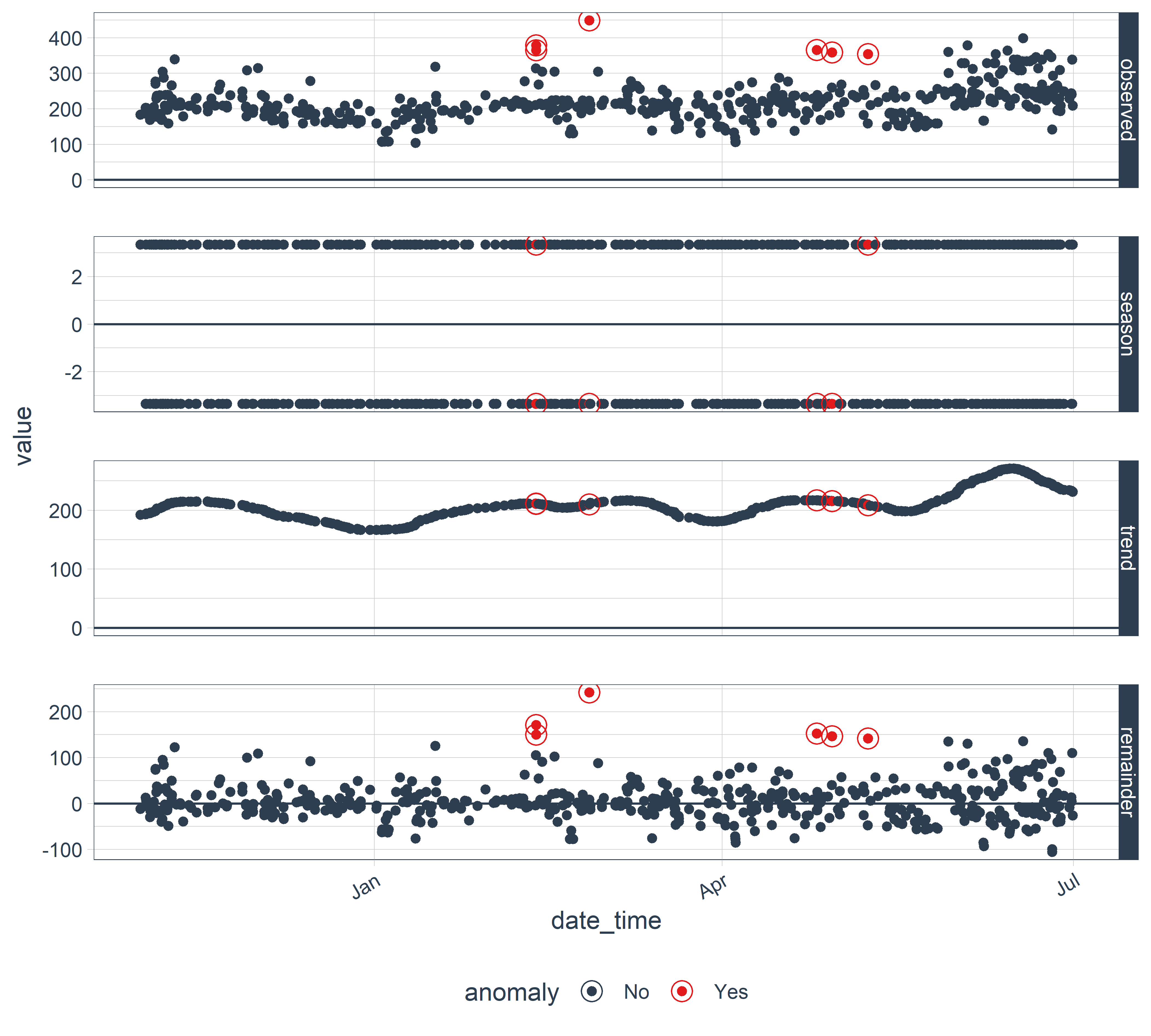
РИСУНОК 9.1: Результат автоматического обнаружения аномалий во временном ряду, выполненного с помощью пакета anomalize
Еще одна функция — plot_anomalies() — позволяет отдельно изобразить исходный временной ряд и обнаруженные в нем необычные наблюдения (рис. 9.2):
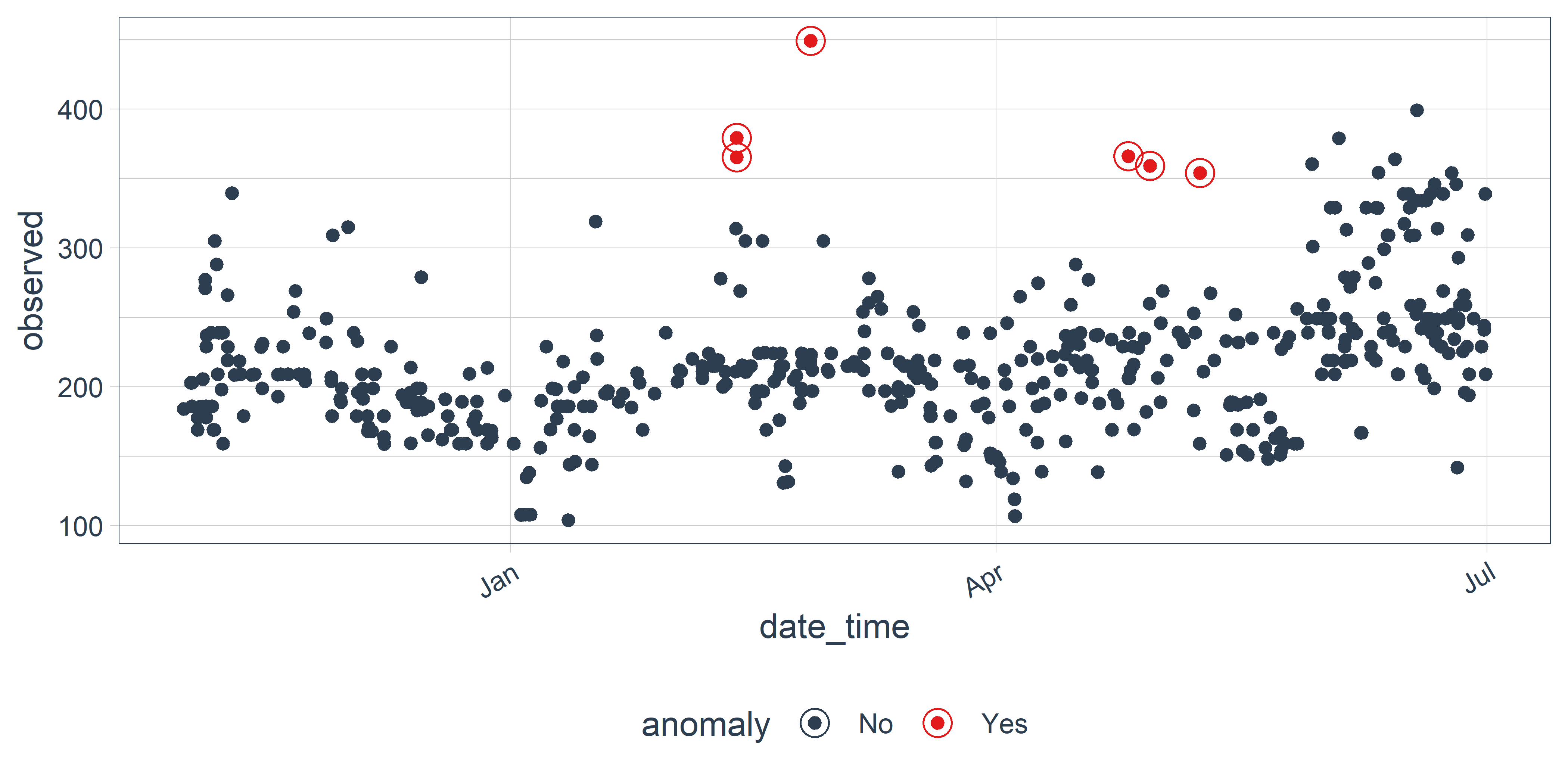
РИСУНОК 9.2: Аномальные наблюдения, автоматически обнаруженные во временном ряду с помощью пакета anomalize
Поскольку plot_anomalies() возвращает графический объект класса ggplot, то при желании мы можем легко добавить к нему другие ggplot–элементы обычным в таких случаях способом. Добавим, например, линию, последовательно соединяющую все точки (рис. 9.3):
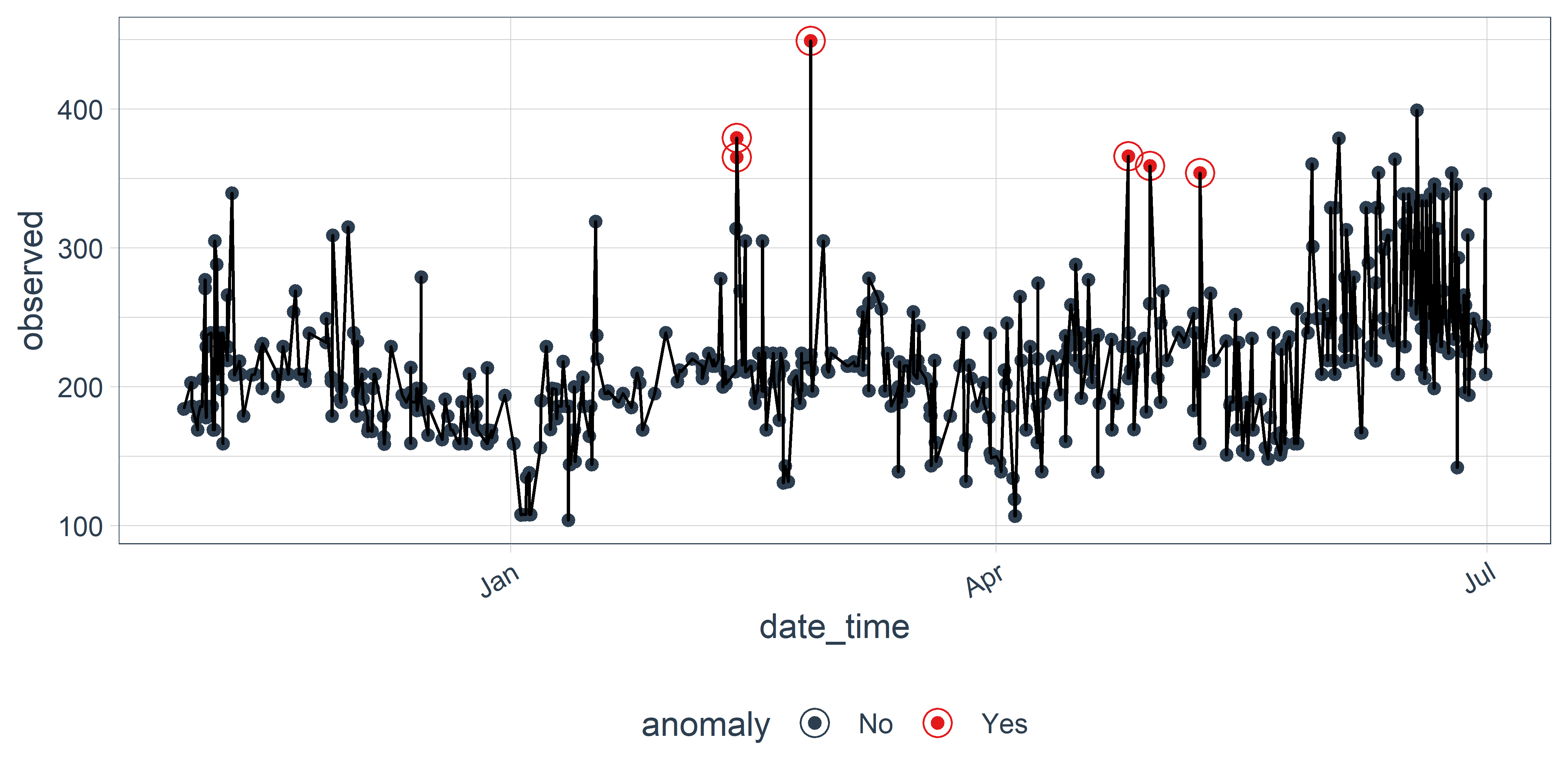
РИСУНОК 9.3: Пример сочетания функции plot_anomalies() из пакета anomalize и функции geom_line() из пакета ggplot2
9.2 Ручная настройка параметров для обнаружения аномалий
При создании объекта result_13252 все вычисления были выполнены с использованием настроек, заданных в пакете anomalize по умолчанию. Часто для получения приемлемого результата этого будет достаточно. Однако, в зависимости от свойств анализируемого временного ряда, иногда потребуется более тонкая настройка соответствующих параметров.
Рассмотрим сначала параметры функции time_decompose(), которая выполняет разложение ряда на отдельные компоненты. Результат работы этой функции в значительной мере зависит от значений следующих ее аргументов:
frequency— определяет “частоту” сезонной компоненты, т.е. число наблюдений, входящих в один сезонный цикл (например, для дневных данных этот аргумент по умолчанию будет равен"1 week", т.е. одной неделе);trend— определяет число наблюдений в отдельных отрезках временного ряда, используемых для расчета тренда (например, для дневных данных по умолчаниюtrend = "3 months", т.е. три месяцам);method— метод, используемый для разложения ряда на компоненты. У этого аргумента есть два возможных значения:"stl"(принято по умолчанию) и"twitter". STL — это классический метод разложения временных рядов на компоненты, в основе которого лежит сглаживание данных по методу нелинейной локальной регрессии (гл. 4). Метод"twitter"— более новый и, как следует из его названия, был предложен исследователями из компании Twitter (Vallis, Hochenbaum, and Kejariwal 2014). В рамках этого метода тренд оценивается путем вычисления медиан в пределах отдельных интервалов времени, на которые разбивает исходный ряд (их длина определяется параметромtrend— см. выше).
По умолчанию аргументы frequency и trend принимают значения "auto" (автоматический режим). В этом случае для выбора конкретных подходящих ситуации значений frequency и trend функция time_decompose() обращается к другой функции — get_time_scale_template(), которая возвращает “справочник” типичных значений:
## # A tibble: 8 x 3
## time_scale frequency trend
## <chr> <chr> <chr>
## 1 second 1 hour 12 hours
## 2 minute 1 day 14 days
## 3 hour 1 day 1 month
## 4 day 1 week 3 months
## 5 week 1 quarter 1 year
## 6 month 1 year 5 years
## 7 quarter 1 year 10 years
## 8 year 5 years 30 yearsВидим, например, что в случае с данными, где промежуток между наблюдениями выражается в секундах, параметры frequency и trend будут выражаться в часах и по умолчанию составят "1 hour" (1 час) и "12 hours" (12 часов) соответственно. Следует отметить однако, что в зависимости от интервала между наблюдениями и длины самого временного ряда, конкретные выбранные программой значения frequency и trend необязательно окажутся равными приведенным выше значениям из “справочника”. Именно это произошло выше при создании объекта result_13252 (frequency = 2 hours, trend = 61 hours). Помимо строковых значений ("1 hour", "2 days", "2 weeks" и т.д.) обоим параметрам можно присваивать и числовые значения (см. ниже) — часто это оказывается более удобным подходом. Отметим также, что “шаблонные” значения параметров frequency и trend можно изменить глобально с помощью функции set_time_scale_template() (пример не приводится).
Для отмены автоматического выбора значений frequency и trend достаточно указать желаемые значения при вызове функции time_decompose(). В приведенном ниже примере мы присвоим этим параметрам значения 2 и 6 (часов) соответственно:
hotels %>%
filter(prop_id == 13252) %>%
time_decompose(price_usd, frequency = 2, trend = 6) %>%
anomalize(remainder) %>%
time_recompose() %>%
plot_anomaly_decomposition()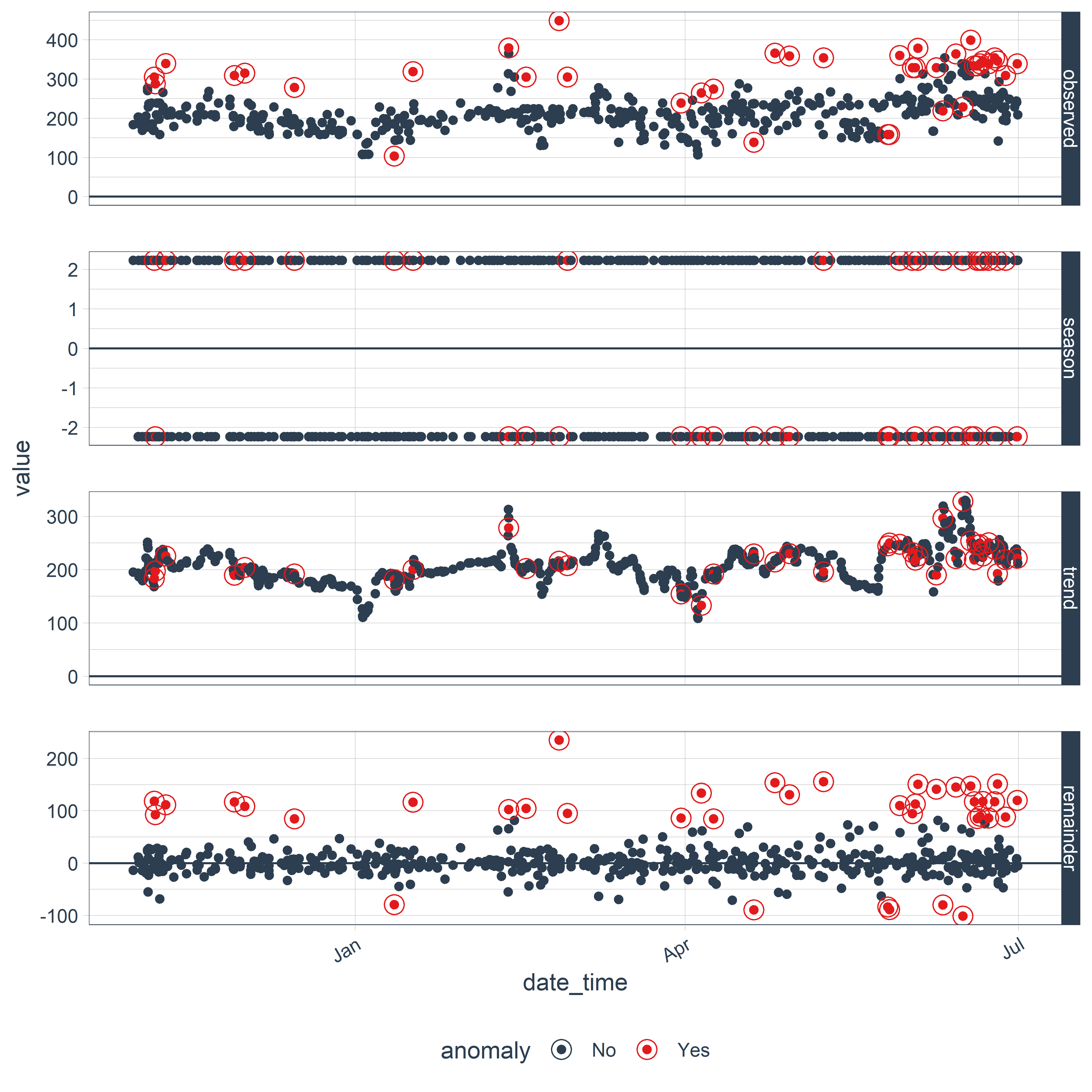
РИСУНОК 9.4: Результат обнаружения аномалий во временном ряду, выполненного с помощью пользовательских настроек функции time_decompose()
Как видно на рис. 9.4, уменьшение параметров frequency и trend привело к классификации большего количества наблюдений как аномалий. Это обычный результат в таких случаях, обусловленный переобучением Loess–модели тренда (обратите внимание на то, какой извилистой стала кривая тренда на рис. 9.4 по сравнению с рис. 9.1). В отличие от Loess, второй метод разложения временных рядов — "twitter" — более устойчив к локальным колебаниям и поэтому при тех же значениях frequency и trend обычно относит к аномалиям меньше наблюдений. Это легко проверить (сравните рис. 9.4 и рис. 9.5):
hotels %>%
filter(prop_id == 13252) %>%
time_decompose(price_usd, frequency = 2,
trend = 6, method = "twitter") %>%
anomalize(remainder) %>%
time_recompose() %>%
plot_anomaly_decomposition()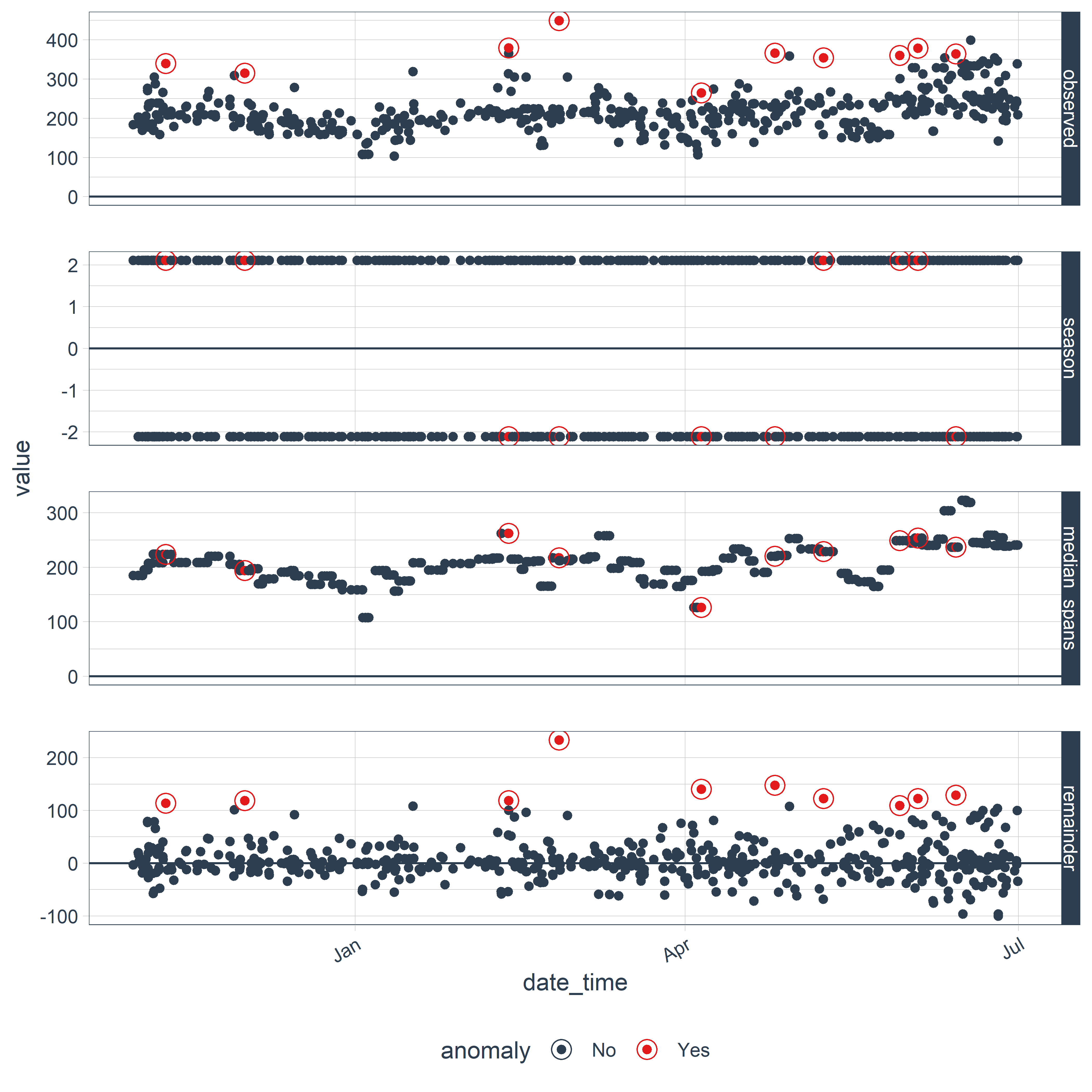
РИСУНОК 9.5: Результат обнаружения аномалий во временном ряду, выполненного по методу twitter
Функция anomalize позволяет выбрать один из двух методов выявления аномальных наблюдений, а также настроить чувствительность этих методов. Для этого служат следующие аргументы функции:
method— принимает два возможных значения в соответствии с названием метода обнаружения аномалий:"iqr"(принято по умолчанию) и"gesd". Метод IQR (от “interquartile range”, т.е. “интерквартильный размах”) работает быстрее, но не так точен, как GESD (Generalized Extreme Studentized Deviate test).alpha— контролирует ширину диапазона “нормальных” значений (по умолчанию равен 0.05). Чем меньше этот параметр, тем шире диапазон значений, рассматриваемых как “нормальные”, и тем меньше наблюдений будут классифицированы как аномальные.max_anoms— максимальная доля наблюдений, которые позволено отнести к аномалиям (0.2 по умолчанию, т.е. 20%).
Рассмотрим влияние параметра alpha, снизив его значение с принятого по умолчанию 0.05 до 0.025. При этом оставим параметры frequency и trend функции time_decompose() такими же, как на рис. 9.4:
hotels %>%
filter(prop_id == 13252) %>%
time_decompose(price_usd,
frequency = 2,
trend = 6,
method = "twitter") %>%
anomalize(remainder, alpha = 0.025) %>%
time_recompose() %>%
plot_anomaly_decomposition()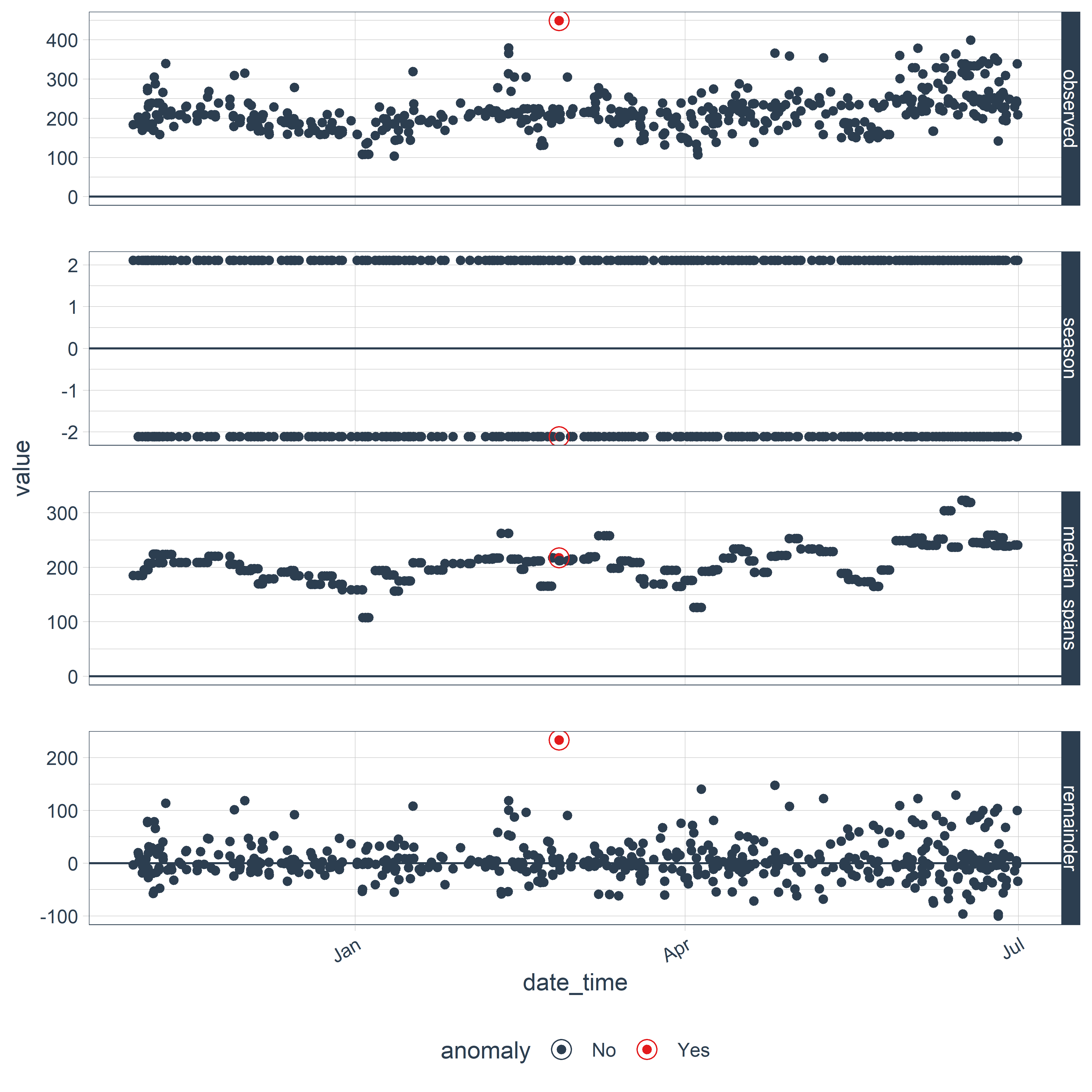
РИСУНОК 9.6: Результат обнаружения аномалий во временном ряду, выполненного с пониженным значением параметра alpha функции anomalize()
Как видно на рис. 9.1, несмотря на все еще имеющее место переобучение Loess–модели тренда, к классу аномальных было отнесено намного меньшее количество наблюдений. Аналогичного эффекта можно было бы добиться также путем снижения параметра max_anoms функции anomalize() (пример не приводится).
9.3 Одновременный анализ нескольких временных рядов
Отличительной особенностью пакета anomalize является возможность параллельно анализировать несколько временных рядов на наличие аномалий. Для этого достаточно в таблице с данными иметь группирующую переменную, которая идентифицирует отдельные ряды. В нашем примере с ценами на гостиничные номера такой одновременный анализ выглядел бы следующим образом (параметрам всех функций здесь присвоены их автоматически выбранные значения; обратите внимание на аргумент time_recompose = TRUE функции plot_anomalies() — он позволяет включить изображение на графике диапазона, в который входят “нормальные” наблюдения):
hotels %>%
group_by_key() %>%
time_decompose(price_usd) %>%
anomalize(remainder) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE)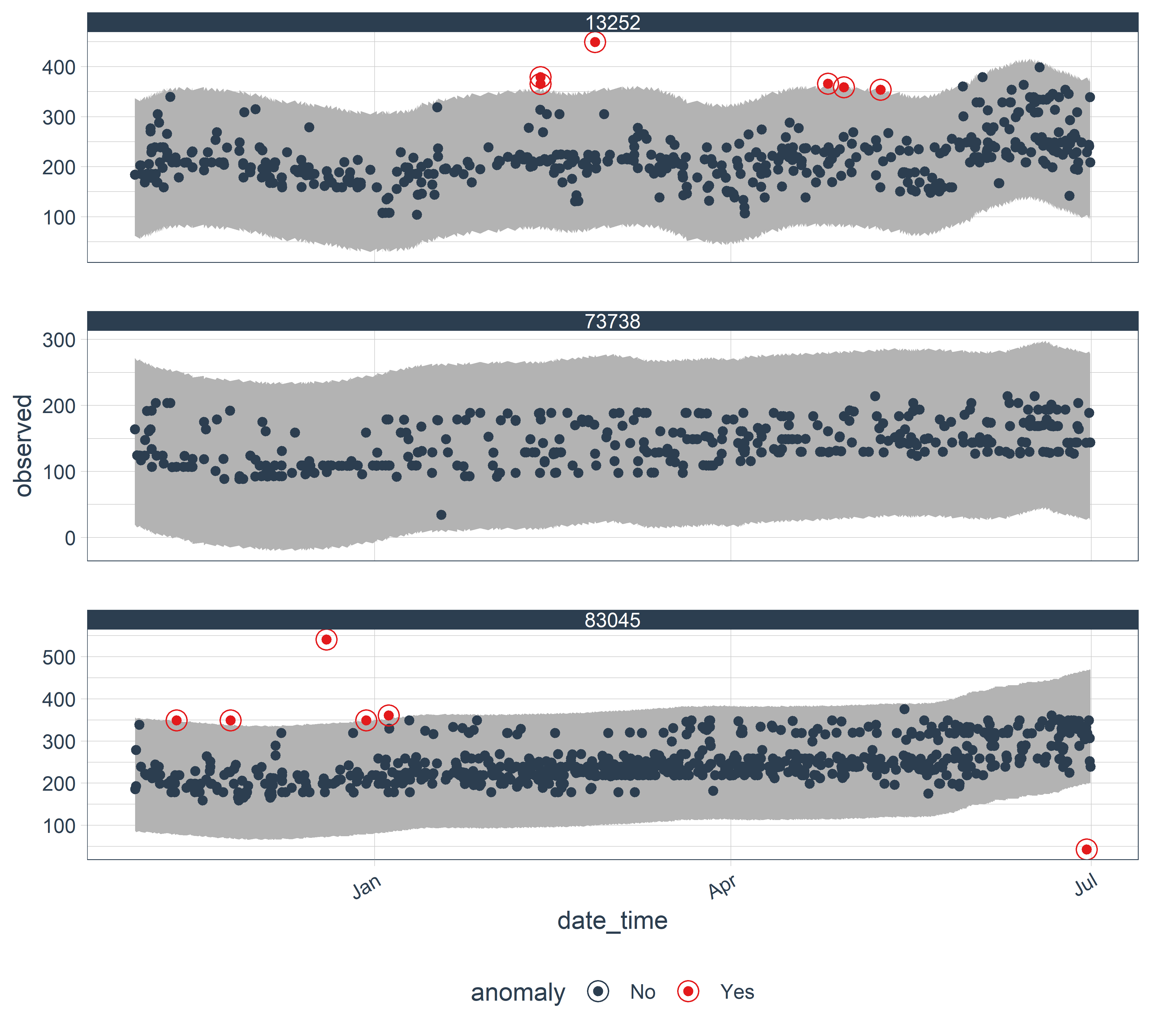
РИСУНОК 9.7: Результат обнаружения аномалий во временном ряду, выполненного с пониженным значением параметра alpha функции anomalize()
Стоит подчеркнуть, что в пакете anomalize нет возможности настраивать параметры функций для отдельных рядов при таком параллельном анализе. Поэтому параллельный анализ имеет смысл выполнять только на рядах, охватывающих примерно одинаковый период, имеющих одинаковую периодичность регистрации наблюдений и, конечно же, описывающих динамику той же переменной. В нашем примере с ценами на гостиничные номера все эти условия выполняются.
На этом мы завершим рассмотрение основных возможностей пакета anomalize для обнаружения необычных наблюдений во временных рядах. Дополнительные примеры работы с этим пакетом, а также более подробное описание лежащих в его основе методов, можно найти в официальной документации.