ГЛАВА 2 Обработка пропущенных наблюдений
Очень часто на практике приходится сталкиваться с пропущенными наблюдениями во временных рядах. Это может стать проблемой при использовании многих методов анализа и моделирования, которые предполагают наличие полных наборов упорядоченных во времени наблюдений. В пакете tsibble (разд. 1.4) есть несколько функций, позволяющих выполнить диагностику данных на наличие пропущенных наблюдений, а также восстановить такие наблюдения с помощью любой подходящей ситуации логики. Для иллюстрации работы с этими функциями мы воспользуемся таблицей shares, которая содержит данные по цене акций компаний Amazon, Facebook и Google (подразд. 1.5.3).
Для начала применим функцию has_gaps(), чтобы узнать о наличии хотя бы одного пропущенного наблюдения в каждом из анализируемых временных рядов:
## # A tibble: 3 x 2
## share .gaps
## <chr> <lgl>
## 1 amzn FALSE
## 2 fb FALSE
## 3 goog FALSEСогласно полученному результату, пропущенных наблюдений нет ни в одном из рядов (все значения в столбце .gaps равны FALSE). Как же так получилось? Ведь мы знаем, что в таблице shares отсутствует большое количество наблюдений!
Дело в том, что с “точки зрения” функции has_gaps() “пробелов” в данных действительно нет, поскольку все отсутствующие наблюдения в явном виде представлены с помощью значений NA (кстати, это хорошая практика). Посмотрим, что произойдет, если мы удалим все NA (после этой операции таблицу нужно заново преобразовать в формат tsibble):
shares_na_dropped <- shares %>%
na.omit() %>%
as_tsibble(key = share, index = ds)
has_gaps(shares_na_dropped)## # A tibble: 3 x 2
## share .gaps
## <chr> <lgl>
## 1 amzn TRUE
## 2 fb TRUE
## 3 goog TRUEТеперь, как видим, функция has_gaps() успешно обнаружила наличие пропущенных наблюдений для некоторых дат. С помощью другой функции — scan_gaps() — можно выяснить, какие именно наблюдения отсутствуют в каждом из рядов:
## # A tsibble: 1,149 x 2 [1D]
## # Key: share [3]
## share ds
## <chr> <date>
## 1 amzn 2016-01-09
## 2 amzn 2016-01-10
## 3 amzn 2016-01-16
## 4 amzn 2016-01-17
## 5 amzn 2016-01-18
## 6 amzn 2016-01-23
## 7 amzn 2016-01-24
## 8 amzn 2016-01-30
## 9 amzn 2016-01-31
## 10 amzn 2016-02-06
## # ... with 1,139 more rowsСтрого говоря, полученный с помощью scan_gaps() результат не совсем верен. Например, для акций компании Amazon эта функция “решила”, что первое пропущенное наблюдение приходится на 9 января 2016 г., тогда как в действительности временной ряд amzn начинается с 1 января 2016 г. и в нем пропущены несколько первых наблюдений (см. подразд. 1.5.3). Впрочем, такой результат вполне логичен, поскольку в ходе создания таблицы shares_na_dropped пропущенные наблюдения в начале ряда были удалены и функция scan_gaps() просто ничего об этом “не знала”.
Функция count_gaps() дает более развернутый отчет по отсутствующим наблюдениям. В частности, она определяет длину каждого “пробела” в каждом временном ряду:
## # A tibble: 552 x 4
## share .from .to .n
## <chr> <date> <date> <int>
## 1 amzn 2016-01-09 2016-01-10 2
## 2 amzn 2016-01-16 2016-01-18 3
## 3 amzn 2016-01-23 2016-01-24 2
## 4 amzn 2016-01-30 2016-01-31 2
## 5 amzn 2016-02-06 2016-02-07 2
## 6 amzn 2016-02-13 2016-02-15 3
## 7 amzn 2016-02-20 2016-02-21 2
## 8 amzn 2016-02-27 2016-02-28 2
## 9 amzn 2016-03-05 2016-03-06 2
## 10 amzn 2016-03-12 2016-03-13 2
## # ... with 542 more rowsОбнаруженные пробелы далее можно легко визуализировать с помощью пакета ggplot2 (рис. 2.1; во избежание плотного перекрытия точек показаны только первые шесть месяцев 2016 г.):
gaps %>%
filter(.to <= as.Date("2016-06-30")) %>%
ggplot(., aes(x = share)) +
geom_linerange(aes(ymin = .from, ymax = .to)) +
geom_point(aes(y = .from)) + geom_point(aes(y = .to)) +
coord_flip() + theme_minimal()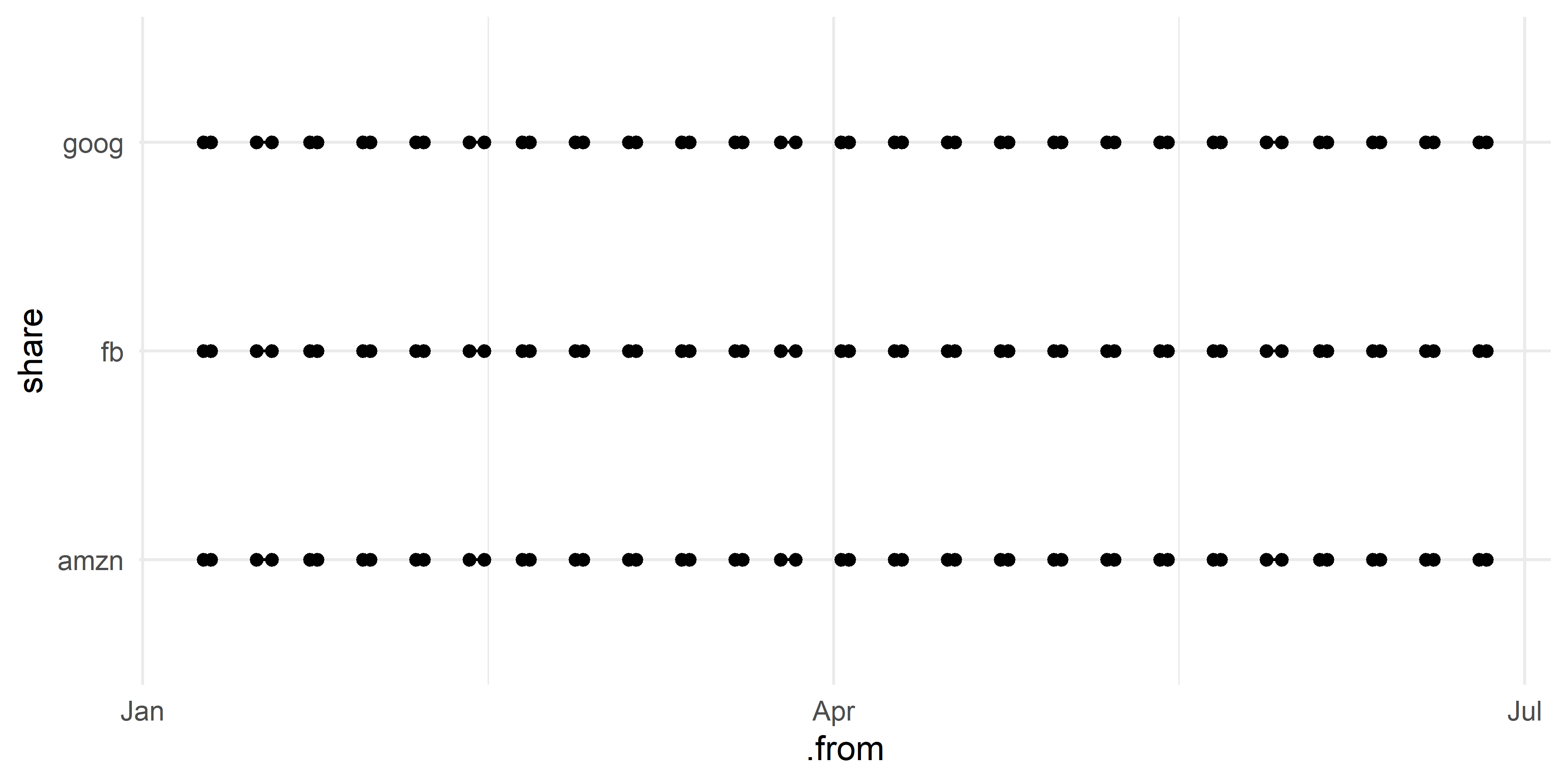
РИСУНОК 2.1: Визуализация пропущенных наблюдений во временных рядах
Как отмечено выше, хорошей практикой является представление пропущенных наблюдений в явном виде с помощью NA. Для этого достаточно воспользоваться функцией fill_gaps() из пакета tsibble:
## # A tsibble: 3,711 x 3 [1D]
## # Key: share [3]
## ds share price
## <date> <chr> <dbl>
## 1 2016-01-04 amzn 637.
## 2 2016-01-05 amzn 634.
## 3 2016-01-06 amzn 633.
## 4 2016-01-07 amzn 608.
## 5 2016-01-08 amzn 607.
## 6 2016-01-09 amzn NA
## 7 2016-01-10 amzn NA
## 8 2016-01-11 amzn 618.
## 9 2016-01-12 amzn 618.
## 10 2016-01-13 amzn 582.
## # ... with 3,701 more rowsК сожалению, многие реализованные в R статистические методы, включая методы моделирования временных рядов, не могут работать с данными, в которых есть NA–значения. Для решения этой проблемы можно попробовать восстановить пропущенные наблюдения тем или иным подходящим ситуации способом. Для восстановления NA–значений во временных рядах amzn, fb и goog в таблице shares мы воспользуемся простой и хорошо подходящей для этого случая стратегией LOCF (“last observation carried forward”), которая заключается в том, что каждое пропущенное значение заменяется на последнее предшествующее ему непропущенное значение (или на ближайшее следующее за ним непропущенное значение, если ряд начинается с NA, как в наших данных). Одну из реализаций метода LOCF можно найти в функции na_locf() из пакета imputeTS. В приведенном ниже коде мы сначала применяем функцию group_by_key() из пакета tsibble для группирования данных по ключевой переменной (share), а затем вызываем функции mutate() (из пакета dplyr) и na_locf() для восстановления пропущенных наблюдений в пределах каждого временного ряда (рис. 2.2):
require(imputeTS)
shares_na_filled <- shares %>%
group_by_key() %>%
mutate(price = na_locf(price))
shares_na_filled %>%
ggplot(., aes(ds, price, color = share)) +
geom_line() + scale_y_log10() +
theme_minimal()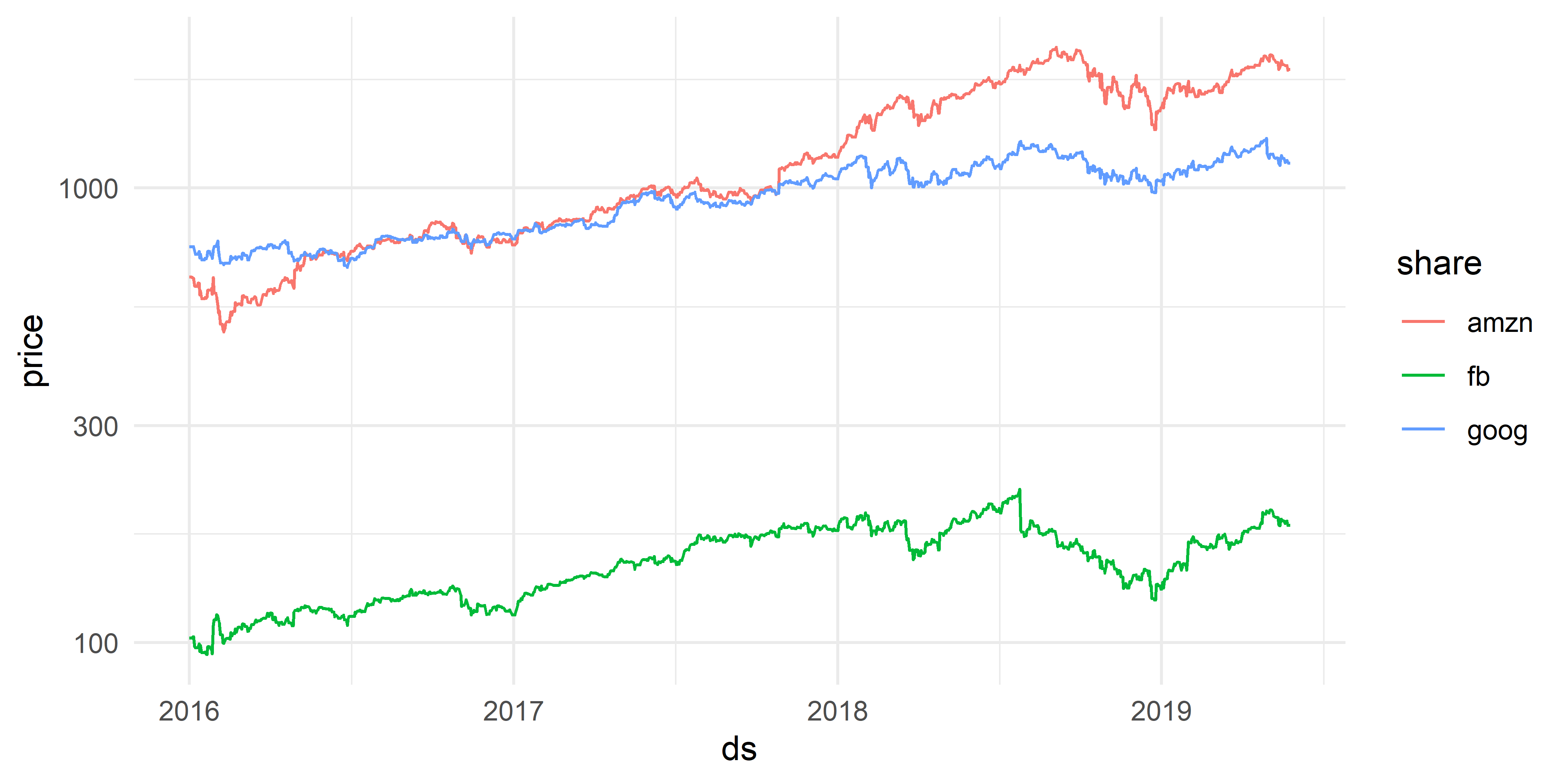
РИСУНОК 2.2: Данные по цене акций трех компаний после восстановления пропущенных наблюдений с помощью метода LOCF (сравните с рис. 1.4)